
Naive Bayes classifier is a set of supervised machine learning algorithms used for classification tasks, like text classification. It is probabilistic model based on the Bayes theorem. It is highly effective in terms of speed when it comes to high dimension data and large datasets. This model predicts the probability of a new datapoint being in a particular class given a set of features. It is called ‘naive’ because it assumes that each input variable is independent. This is a strong assumption and is unrealistic for real dataset however, the technique is very effective on a large range of complex problems.
 |
| Fig. Naive Bayes Classifier [Source] |
What is Bayes Theorem ?
Bayes’ Theorem is a mathematical principle that calculates the probability of an event by taking into account prior knowledge of related conditions. Essentially, it enhances our understanding of conditional probability.
Bayes’ Theorem, named after Thomas Bayes, is a mathematical concept that enables us to determine the probability of an event, given certain conditions or evidence. In simpler terms, Bayes’ Theorem is a way of finding a probability when we know certain other probabilities.
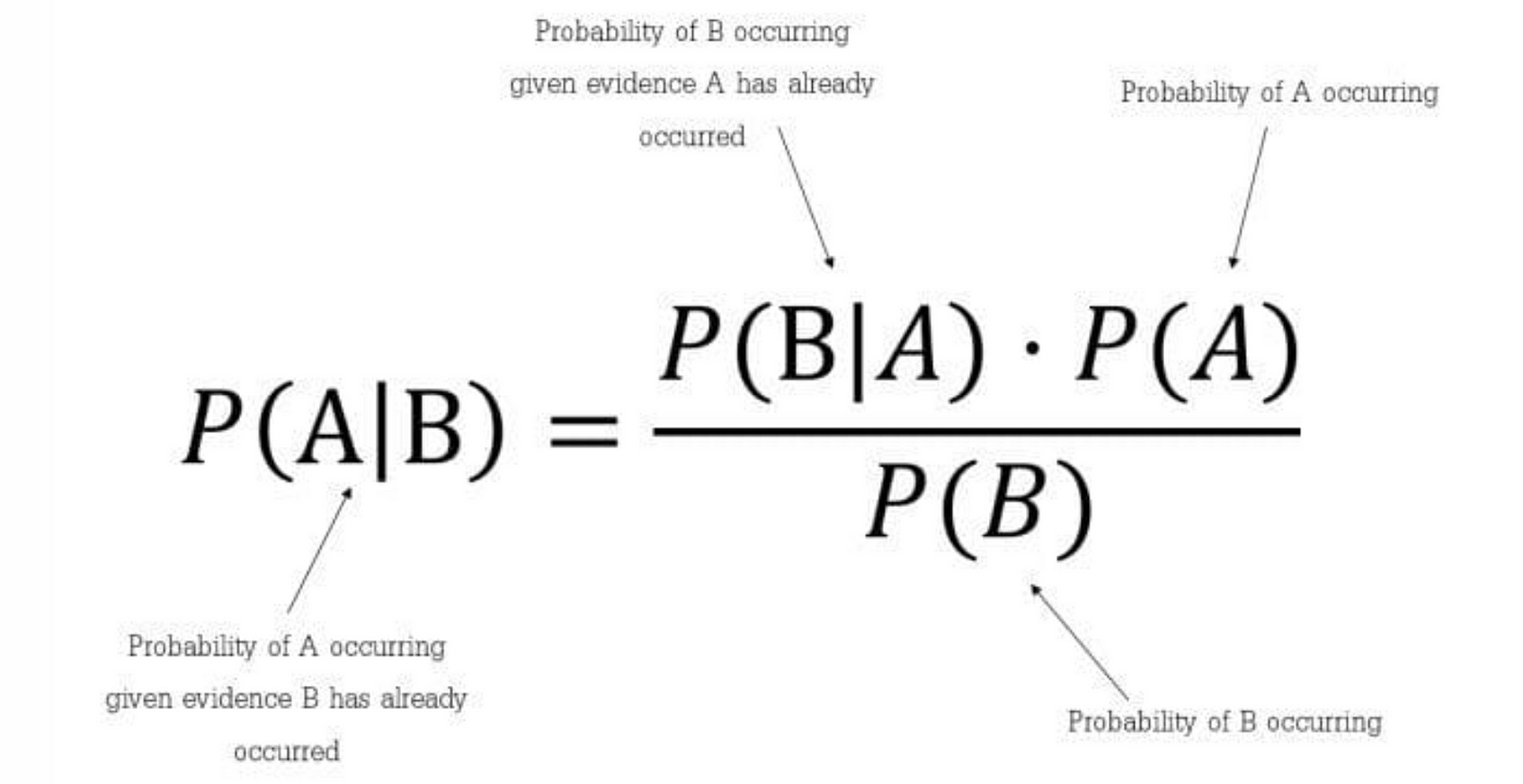
It builds upon conditional probability, denoted as P(B|A), where we find the probability of B given A. Bayes’ Theorem allows us to calculate the probability of A given B, provided we know the prior probabilities of B and A, denoted as P(B) and P(A) respectively. Thomas Bayes originally introduced this theorem, utilizing conditional probability to create an algorithm that uses evidence to estimate unknown parameters.
The theorem involves two main types of probabilities:
- Prior probability, P(B) & P(A)
- Posterior probability, P(A|B)
where A and B are events and P(B) ≠ 0
 |
| Fig. Bayes Theorem [Source] |
Basically, we are trying to find probability of event A, given the event B is true. Event B is also termed as evidence.
- P(A) is the priori of A (the prior probability, i.e. Probability of event before evidence is seen). The evidence is an attribute value of an unknown instance (here, it is event B).
- P(B) is Marginal Probability: Probability of Evidence.
- P(A|B) is a posteriori probability of B, i.e. probability of event after evidence is seen.
- P(B|A) is Likelihood probability i.e the likelihood that a hypothesis will come true based on the evidence.
Which tells us: how often A happens given that B happens, written P(A|B) also the posterior probability, When we know: how often B happens given that A happens, written P(B|A) also called likelihood; and how likely A is on its own, written P(A) also called class prior probability; and how likely B is on its own, written P(B) also called predictor prior probability. Read more on Bayes theorem here.
Working of Naive Bayes
Lets us take a sample very common weather dataset and see how naive bayes works on this. Every dataset has two parts: features and the response. The feature matrix are the columns with values that will be given to the model to classify to which class this new belongs, called dependent features. The response matrix is the value of the class (prediction or output) for the row, this is used by the algorithm to further prediction when a new set of row with value is given. Here, Outlook, Temperature, Humidity and Windy are the features and Play is response.
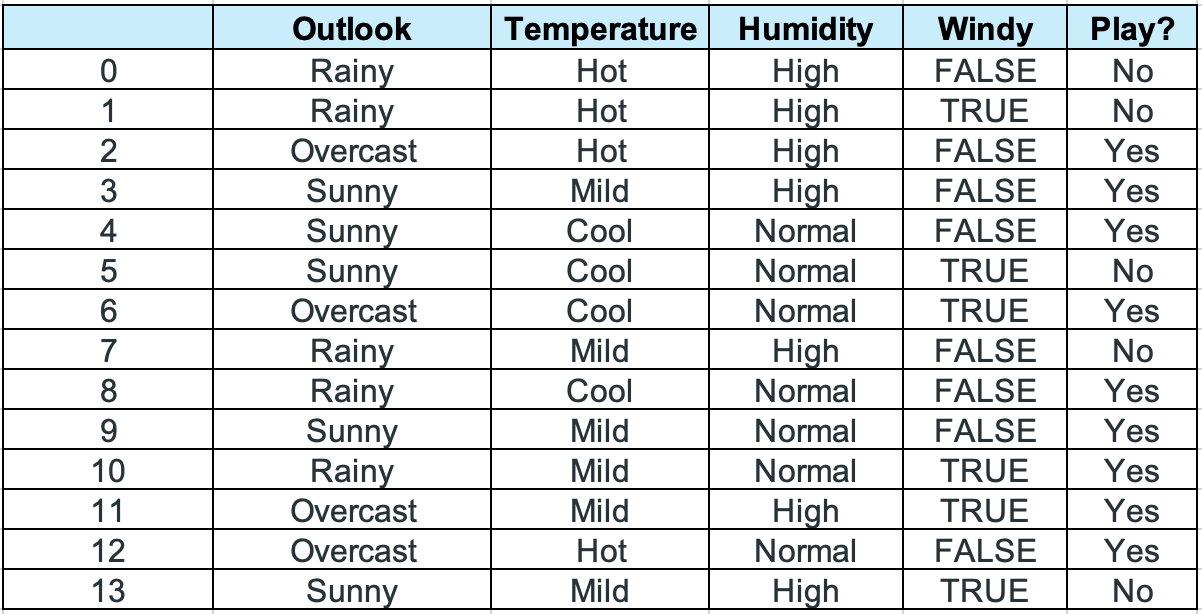 |
| Fig. Dataset — Weather |
Now lets say you want to decide whether or not you want to play based on these features, so lets take a new set of features:
today = (Sunny, Hot, Normal, False)
So lets, find out if you are going to play, remember this algorithm considers independence among the features. So, as we know probability of two independent events is given by,
P(A,B) = P(A).P(B)
Hence, we can write the probability of you playing to be as —
P(Yes∣today) = P(Sunny_Outlook∣Yes).P(Hot_Temperature∣Yes).P(Normal_Humidity∣Yes).P(No_Wind∣Yes).P(Yes) / P(today)
And, the probability of you not going to play is given by —
P(No∣today) = P(Sunny_Outlook∣No).P(Hot_Temperature∣No).P(Normal_Humidity∣No).P(No_Wind∣No).P(No) / P(today)
Now we need to find these values for the probabilities, for which we need to do some pre-computations on our dataset.
First check the total number of rows in our dataset, thats 14. Next check the number of yes and no, which is 9 and 5 respectively.

Next up lets check for each feature the possible values and the yes and no probabilities for each of those values.
Lets do first for outlook, here you see we have 3 different possible values — Rainy, Sunny, Overcast. Now you have got to count the number of times it is sunny and we play (i.e. a yes in play column and sunny in outlook column). Next, check for sunny and no. And similarly for rainy and yes, rainy and no, overcast and yes, overcast and no. Get all these values in the table as shown. Then now we have total of 9 yes and 5 no. So the probability of outlook feature value sunny, for yes is 2/9 and for no is 3/5. Similarly computing all the other values for outlook you will get the table as below.

Now repeat the same process for the rest of the features that is Temperature, Humidity and wind and you will get tables as shown below.



Now we have all the pre-computations ready now lets use these values and put them in the formula discussed above and find the probability of playing today.
So, calculating for yes we will get,
P(Yes∣today) =
P(Sunny_Outlook∣Yes).P(Hot_Temperature∣Yes).P(Normal_Humidity∣Yes).P(No_Wind∣Yes).P(Yes) / P(today)
= 3/9 * 2/9 * 6/9 * 6/9 * 9/14
= 0.02116
and calculating for no we get,
P(No∣today) = P(Sunny_Outlook∣No).P(Hot_Temperature∣No).P(Normal_Humidity∣No).P(No_Wind∣No).P(No) / P(today)
= 3/5 * 2/5 * 1/5 * 2/5 * 5/14
= 0.0068
Now you can normalize these values if you want as the sum should be 1 for the two probabilities. But here as we can see the probability of playing as yes ia more than no, even after normalizing the probability of yes would be more hence we can conclude with the prediction as playing = yes for the new set of features as sunny, hot, normal, false.
References
- https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/#:~:text=Naive%20Bayes%20classifier%20is%20a,spam%20filtering%2C%20and%20recommendation%20systems.
- https://www.geeksforgeeks.org/naive-bayes-classifiers/
- https://scikit-learn.org/stable/modules/naive_bayes.html
- https://towardsdatascience.com/naive-bayes-classifier-81d512f50a7c
- https://www.kdnuggets.com/2020/06/naive-bayes-algorithm-everything.html
Nice explanation
ReplyDelete