
Support Vector Machine, SVM is a supervised machine learning algorithm best suited for classification purposes. It can be used for various different applications like linear and non linear classification, regression and even outlier detection. SVM is preferred more over other classification techniques like logistic regression or KNN as it can handle high dimensional data and also can be used for non-linear classification.

Like in linear regression, the algorithm tries to find the best fit line to have the maximum points on that line. In SVM, the main objective is to find the best optimal hyperplane in an N-dimensional space that can separate the data points in different classes. Basically we want the margin distance of the hyperplane to be as large as possible from the two closest data points of two different classes.
The dimension of the hyperplane depends on the number of features, so if you have two features then you are going to have a single lined hyperplane and if you have 3 input features then the hyperplane will be a 2D plane. As the number of features or the dependent variables increases so does the dimensions of our hyperplane and hence gets more complex to imagine.
Linear SVM — when the data points can be can be classified into two classes with a single straight line (in case of 2D space and plane in a 3D space), that means that the data is linearly separable.
Non Linear SVM — when the data points cannot be classified by a straight line(in case of 2D) into two classes, but can be classified using advanced kernel techniques like polynomial or sigmoid, this data is called not linearly separable.
How does SVM work ?
There can be multiple lines/decision boundaries to segregate the classes in n-dimensional space, but we need to find out the best decision boundary that helps to classify the data points. This best boundary is known as the hyperplane of SVM.
The data points or vectors that are the closest to the hyperplane and which affect the position of the hyperplane are termed as Support Vector. Since these vectors support the hyperplane, hence called a Support vector as can be seen in the image below.
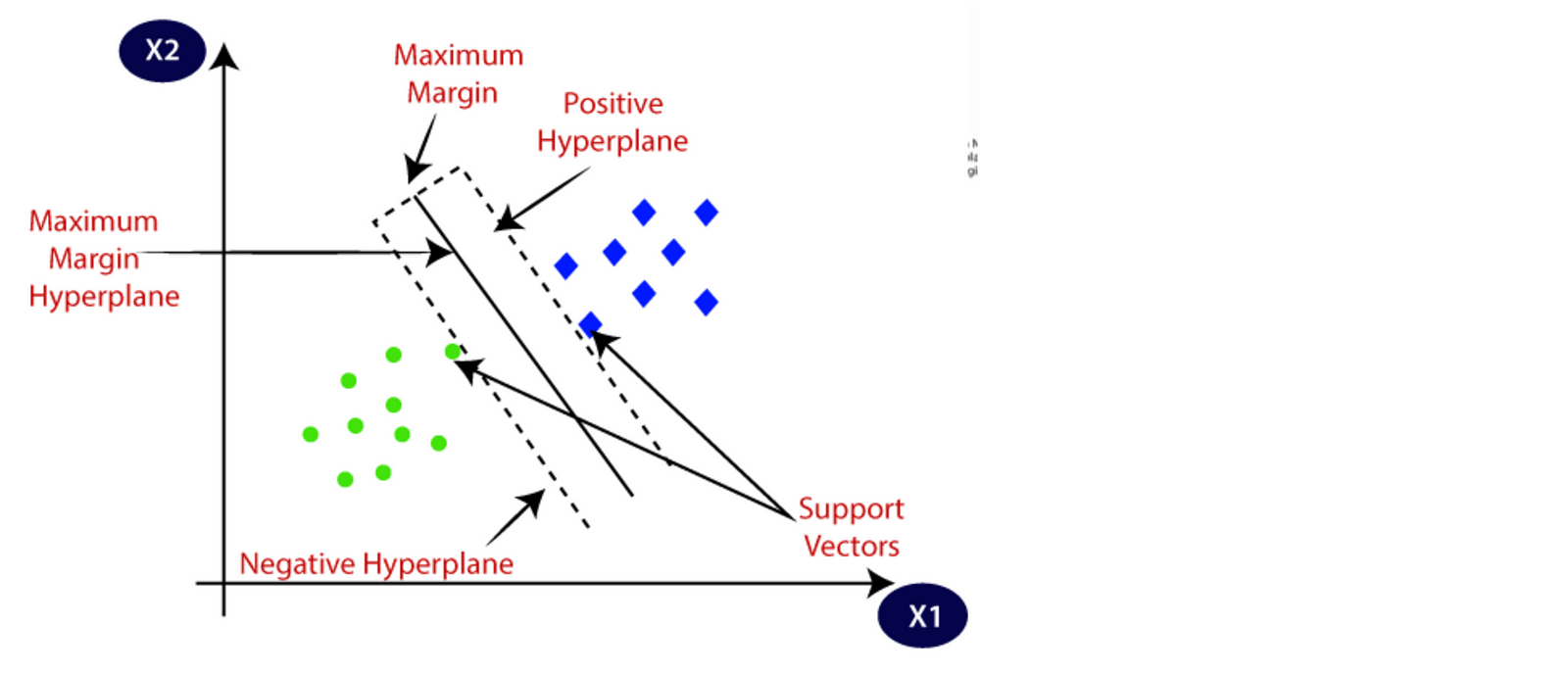 |
| Fig. SVM [Source] |
Here the x1 and x2 are the independent variables. The data points closest to the other class are called support vector. It is here that the hyperplane has the margin lines and the mid between them that gets the highest distance from both the support vectors is the maximum margin hyperplane.
Lets consider an example, say we have data points given as below and we want to classify a new data point there that is in red, and we want to find out which class it belongs to — Blue or green.
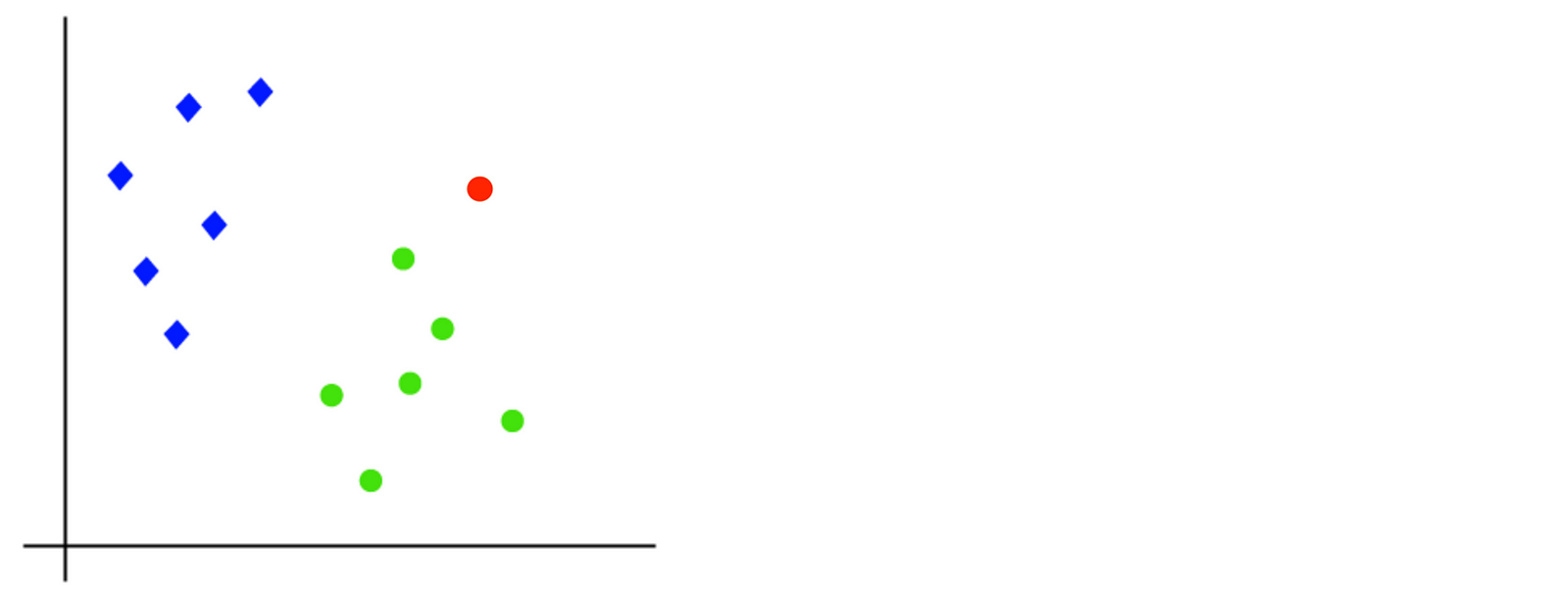
Now the algorithm only knows the co-ordinates of all of these data points and as it is 2-d space so by just using a straight line, we can easily separate these two classes. But there can be multiple lines that can separate these classes, which is the best that will separate the two classes.
Hence, the SVM algorithm helps to find the best line or decision boundary; this best boundary or region the hyperplane. SVM algorithm finds the closest point of the lines from both the classes, support vectors. The distance between the vectors and the hyperplane is called as margin. And the goal of SVM is to maximize this margin. The hyperplane with maximum margin is called the optimal hyperplane.
The equation for the linear hyperplane can be written as:
![]()
The vector W represents the normal vector to the hyperplane. i.e the direction perpendicular to the hyperplane. The parameter b in the equation represents the offset or distance of the hyperplane from the origin along the normal vector w. This is the standard equation of any plane and the vectors here are the support vector.
The distance between a data point x_i and the decision boundary can be calculated as:

where ||w|| represents the Euclidean norm of the weight vector w. Euclidean norm of the normal vector W. Using the support vectors the distances are calculated and then the maximised for hard or soft margin whatever may be the case and the the maximum distance is used then to form the final hyperplane equation.
* NOTE *
Hard Margin - The maximum-margin hyperplane or the hard margin hyperplane is a hyperplane that properly separates the data points of different categories without any misclassifications.
Soft Margin - When the data is not perfectly separable or contains outliers, SVM permits a soft margin technique. Each data point has a slack variable introduced by the soft-margin SVM formulation, which softens the strict margin requirement and permits certain misclassifications or violations. It discovers a compromise between increasing the margin and reducing violations.
After all the computations are done and the equation is ready we put in the value of x for the data point we want to classify and find the out the class it belongs to using this (for Linear SVM classifier):

So, we can classify the red point after all such computations and then it would classify the point belongs to the Green class and the other details of optimal hyperplane as given below.
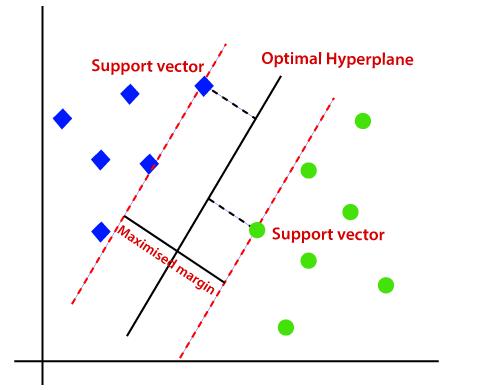
This article only looks into linear SVM.
References
- https://www.geeksforgeeks.org/support-vector-machine-algorithm/
- https://www.javatpoint.com/machine-learning-support-vector-machine-algorithm
- https://www.analyticsvidhya.com/blog/2021/10/support-vector-machinessvm-a-complete-guide-for-beginners/
- https://scikit-learn.org/stable/modules/svm.html